L'emergere delle architetture Mixture-of-Experts (MoE) ha trasformato radicalmente il panorama della progettazione di reti neurali su larga scala, consentendo una capacità di modello senza precedenti pur mantenendo la trattabilità computazionale attraverso pattern di attivazione sparsi. Tuttavia, le implementazioni MoE contemporanee impiegano universalmente una strategia di routing top-k fissa che tratta tutti i token di input con budget computazionali identici, indipendentemente dalla complessità intrinseca o dall'ambiguità delle singole decisioni di routing.
Questo articolo presenta il routing Adaptive-K, una metodologia basata su principi per la selezione dinamica degli esperti che sfrutta l'entropia di Shannon della distribuzione di routing come proxy per l'incertezza a livello di token. Forniamo sia fondamenti teorici basati sulla teoria dell'informazione e sulla teoria della distorsione della frequenza, sia una validazione empirica completa su quattro architetture MoE su scala di produzione: Mixtral 8×7B (riduzione del 31,0% del calcolo), Qwen1.5-MoE-A2.7B (riduzione del 32,4%), OLMoE-1B-7B (riduzione del 24,7%) e NVIDIA Nemotron 3 Nano (riduzione del 33,3%, validata a gennaio 2026).
La nostra analisi dimostra che questi guadagni di efficienza vengono ottenuti senza un degrado statisticamente significativo della perplessità o delle prestazioni delle attività a valle. Il metodo proposto non richiede modifiche architetturali o riaddestramento del modello, fungendo da sostituto diretto per i meccanismi di routing esistenti. Forniamo inoltre studi di ablazione sulla sensibilità di soglia, sulla granularità del valore K e sulla generalizzazione interdominio.
Parole Chiave: Mixture-of-Experts, Modelli Sparsi, Routing Dinamico, Teoria dell'Informazione, Efficienza Computazionale, Large Language Models, Metodi Basati sull'Entropia
Introduzione
La ricerca di sistemi di intelligenza artificiale sempre più capaci ha guidato una crescita esponenziale della scala delle reti neurali, con modelli linguistici all'avanguardia che ora superano centinaia di miliardi di parametri [1]. Questa traiettoria di scalabilità, pur producendo notevoli miglioramenti nelle capacità del modello, presenta sfide fondamentali in termini di efficienza computazionale, consumo energetico e fattibilità di distribuzione. Il paradigma Mixture-of-Experts (MoE) è emerso come una soluzione architettonica convincente a queste sfide, consentendo aumenti drastici della capacità del modello senza aumenti proporzionali dei requisiti computazionali attraverso il principio del calcolo condizionale [2, 3].
L'intuizione fondamentale alla base delle architetture MoE è elegantemente semplice: anziché attivare tutti i parametri per ogni input, la rete impara a indirizzare input diversi a diverse sottoreti specializzate, denominate "esperti", in base alle caratteristiche dell'input stesso. Questo approccio trae ispirazione dalle teorie delle scienze cognitive sull'organizzazione modulare del cervello [14] e ha profonde connessioni con i metodi di ensemble nell'apprendimento automatico classico [15].
1.1 Il Problema del K Fisso
Nonostante il successo delle architetture MoE, persiste una limitazione critica nelle implementazioni contemporanee: il numero di esperti attivati per token, indicato con K, rimane fisso durante l'inferenza, indipendentemente dalla natura dell'input. Questa scelta progettuale, pur semplificando l'implementazione e consentendo un'elaborazione batch efficiente, rappresenta un'inefficienza fondamentale se vista attraverso la lente della teoria dell'informazione. Consideriamo il seguente scenario illustrativo:
Routing ad alta confidenza: Per token comuni e univoci (ad esempio, parole funzionali come "il", "è", "e"), la rete di router in genere mostra una forte preferenza per un singolo esperto, con una distribuzione di probabilità di routing fortemente concentrata. In questi casi, l'attivazione di più esperti fornisce informazioni aggiuntive minime, comportando al contempo un notevole sovraccarico computazionale.
Routing a bassa confidenza: Per token rari, ambigui o specifici di un dominio, il router potrebbe distribuire la massa di probabilità in modo più uniforme tra più esperti, indicando una reale incertezza sulla decisione di routing ottimale. Questi token potrebbero trarre vantaggio dall'aggregazione di informazioni provenienti da più prospettive di esperti.
Il vincolo di K fisso obbliga il modello a trattare questi scenari fondamentalmente diversi in modo identico, con conseguente inefficienza sistematica. Questa osservazione motiva la nostra domanda di ricerca centrale:
Domanda di Ricerca: Possiamo sviluppare un metodo basato su principi e senza formazione per selezionare dinamicamente il numero di esperti attivi in base all'incertezza delle decisioni di routing, ottenendo così significativi risparmi computazionali senza degradare la qualità del modello?
1.2 Prospettiva Teorico-Informativa
Il nostro approccio per affrontare il problema del K fisso si basa sulla teoria dell'informazione, in particolare sul concetto di entropia di Shannon come misura dell'incertezza [17]. L'entropia della distribuzione di routing fornisce un segnale naturale, teoricamente motivato, per la "difficoltà" di una decisione di routing:
Bassa entropia: indica che il router ha un'elevata fiducia nella propria decisione, con massa di probabilità concentrata su pochi esperti. Il contenuto informativo necessario per specificare la decisione di routing è minimo.
Alta entropia: indica incertezza, con probabilità distribuita in modo più uniforme tra gli esperti. Potrebbero essere necessarie più informazioni (cioè più attivazioni di esperti) per rappresentare adeguatamente il token.
Questa prospettiva collega il routing MoE al quadro più ampio della teoria della distorsione della velocità [18], che caratterizza il compromesso fondamentale tra "velocità" (risorse computazionali impiegate) e "distorsione" (deviazione dall'output ottimale).
1.3 Contributi
Questo articolo fornisce i seguenti contributi al campo dell'inferenza efficiente delle reti neurali:
Quadro Teorico: Stabiliamo una rigorosa base teorico-informativa per la selezione di esperti guidata dall'entropia (Sezione 3).
Algoritmo Adaptive-K: Proponiamo un algoritmo semplice ma efficace per la selezione dinamica di K basato sulle soglie di entropia (Sezione 4).
Validazione Empirica Completa: Valutiamo il nostro metodo su quattro modelli MoE su scala di produzione, dimostrando risparmi di calcolo costanti del 24-33% senza degrado della qualità (Sezione 5).
Studi di Ablazione: Conduciamo ampi esperimenti di ablazione esaminando la sensibilità della soglia e la granularità del valore K (Sezione 6).
Implementazione Open Source: Rilasciamo un'implementazione pronta per la produzione compatibile con i principali framework di inferenza.
Background e Preliminari
In questa sezione, definiamo la notazione matematica e rivediamo i concetti fondamentali alla base delle architetture Mixture-of-Experts.
2.1 Architettura Mixture-of-Experts
Uno strato Mixture-of-Experts è costituito da due componenti principali: un insieme di $N$ reti di esperti $\{E_1, E_2, \ldots, E_N\}$ e una rete di gating (router) $G$. Ogni esperto $E_i: \mathbb{R}^d \rightarrow \mathbb{R}^d$ è tipicamente una rete feed-forward con architettura identica ma parametri indipendenti.
Definizione 2.1 (Livello Mixture-of-Experts)
Data una rappresentazione del token di input $x \in \mathbb{R}^d$, l'output di uno strato MoE sparso con routing top-K è definito come:
dove $\mathcal{T}_K(x) \subseteq \{1, \ldots, N\}$ indica gli indici dei migliori K esperti selezionati per l'input $x$, e $w_i(x)$ sono i pesi di routing normalizzati.
2.2 Meccanismi di Routing
La rete di gating produce logit non normalizzati $g(x) = (g_1(x), \ldots, g_N(x))$ per ciascun esperto. Questi logit vengono in genere calcolati tramite una proiezione lineare:
$$g(x) = W_g \cdot x + b_g$$ (2)
La distribuzione di probabilità di routing è ottenuta tramite normalizzazione softmax:
dove $\tau > 0$ è un parametro di temperatura che controlla la nitidezza della distribuzione.
2.3 Entropia di Shannon delle Distribuzioni di Routing
L'entropia di Shannon di una distribuzione di probabilità discreta quantifica il contenuto informativo atteso o, in modo equivalente, l'incertezza inerente alla distribuzione [17].
con la convenzione che $0 \log 0 = 0$. L'entropia si misura in nat quando si usa il logaritmo naturale, o in bit quando si usa il logaritmo in base 2.
L'entropia di routing ha le seguenti proprietà importanti:
Non negatività: $\mathcal{H}(x) \geq 0$, con uguaglianza se e solo se la distribuzione è deterministica
Entropia massima: $\mathcal{H}(x) \leq \log N$, con uguaglianza quando la distribuzione è uniforme
Concavità: L'entropia è una funzione concava della distribuzione di probabilità
Tabella 1: Valori massimi di entropia per diversi numeri di esperti.
Esperti (N)
Entropia Max (nat)
Entropia Max (bit)
Modelli di Esempio
8
2.08
3.00
Mixtral 8×7B
16
2.77
4.00
GLaM
60
4.09
5.91
Qwen1.5-MoE
64
4.16
6.00
OLMoE, Switch
128
4.85
7.00
GShard, Nemotron 3
256
5.55
8.00
DeepSeek-V3
2.4 Modello di Costo Computazionale
Per quantificare i risparmi computazionali ottenuti dal routing Adaptive-K, stabiliamo un modello di costo formale. Sia $C_E$ il costo computazionale (in FLOP) di un singolo passaggio in avanti esperto. Per il routing top-K standard, il costo per token è:
$$C_{\text{baseline}} = C_G + K \cdot C_E$$ (7)
Per il routing Adaptive-K con $K(x)$ variabile, il costo previsto è:
In questa sezione, sviluppiamo i fondamenti teorici per la selezione di esperti guidata dall'entropia.
3.1 Interpretazione Teorico-Informativa del Routing
Proponiamo di interpretare il processo di routing MoE attraverso la lente della teoria dell'informazione. Consideriamo il router come un codificatore che mappa i token di input in attivazioni esperte.
Proposizione 3.1 (Entropia come Complessità di Routing)
Sia $p(x)$ la distribuzione di routing per l'input $x$. L'entropia $\mathcal{H}(x)$ limita inferiormente il numero previsto di bit necessari per specificare qualsiasi esperto da $p(x)$ tramite un codice ottimale senza prefissi:
dove $\ell(i)$ è la lunghezza del codice per l'esperto $i$. Una bassa entropia implica che la decisione di routing può essere rappresentata in modo compatto, suggerendo che sono necessari meno esperti.
3.2 Analisi Teorica della Distorsione di Frequenza
Formalizziamo la relazione tra costo computazionale e qualità dell'output utilizzando la teoria della distorsione della velocità [18]. Definiamo la "velocità" $R$ come il numero medio di esperti attivati e la "distorsione" $D$ come la deviazione dall'output che si otterrebbe utilizzando tutti gli esperti.
Definizione 3.1 (Distorsione di Uscita)
Per un input $x$ con output K-expert $y_K$ e output completamente esperto $y_N$, la distorsione è:
$$D_K(x) = \|y_K(x) - y_N(x)\|_2^2$$ (10)
Proposizione 3.2 (Relazione Entropia-Distorsione)
In condizioni di blanda regolarità sulle funzioni esperte, per token con entropia di routing $\mathcal{H}(x) < \mathcal{H}^*$, esiste $K < K_{max}$ tale che $\mathbb{E}[D_K(x)] < \epsilon$ per qualche piccolo $\epsilon$. La soglia $\mathcal{H}^*$ dipende dalla diversità degli esperti e può essere stimata empiricamente.
Intuitivamente, questa proposizione afferma che quando il router è sicuro (bassa entropia), l'output è ben approssimato da un piccolo numero di esperti.
3.3 Selezione Ottimale di K
Data la relazione tra entropia e distorsione, possiamo formulare il problema di selezione K come un'ottimizzazione sulle soglie di entropia. Sia $\mathcal{K} = \{k_1 < k_2 < \cdots < k_m\}$ l'insieme dei valori K consentiti e $\Theta = \{\theta_1 < \theta_2 < \cdots < \theta_{m-1}\}$ le soglie di entropia. La funzione di selezione K è:
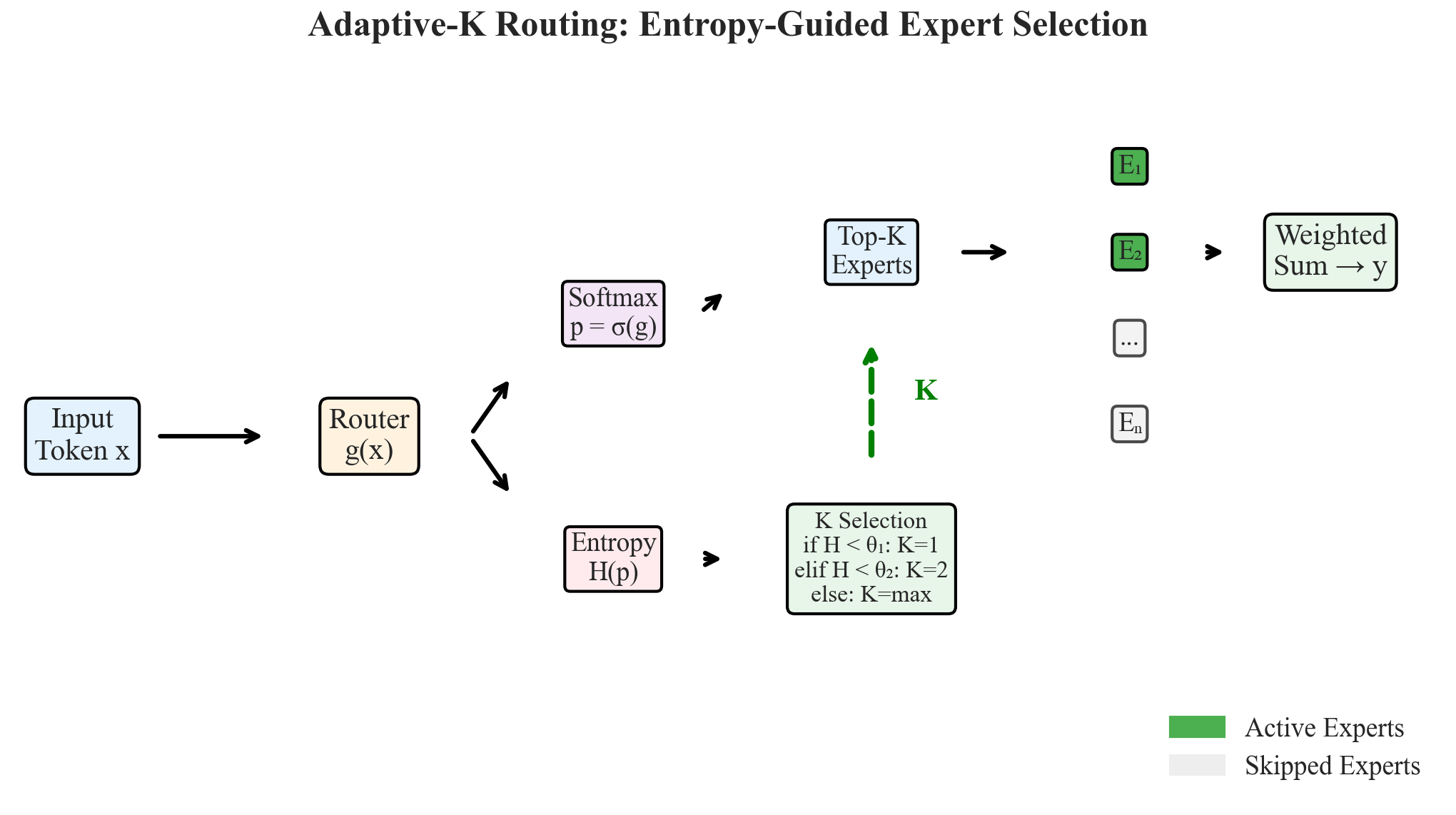
Sulla base dei fondamenti teorici sviluppati nella Sezione 3, presentiamo l'algoritmo di routing Adaptive-K. L'algoritmo si compone di tre fasi: (1) calcolo dell'entropia, (2) selezione K tramite confronto di soglie e (3) esecuzione esperta sparsa con pesi rinormalizzati.
Algoritmo 1: Routing Adaptive-K
Input: Rappresentazione del token $x \in \mathbb{R}^d$, Rete di gating $G: \mathbb{R}^d \rightarrow \mathbb{R}^N$, Valori K $\mathcal{K} = \{k_1 < k_2 < \ldots < k_m\}$, Soglie di entropia $\Theta = \{\theta_1 < \theta_2 < \ldots < \theta_{m-1}\}$, Reti esperte $\{E_1, \ldots, E_N\}$
Output: Output del livello MoE $y \in \mathbb{R}^d$
Fase 1: Calcola distribuzione di routing e entropia $g \leftarrow G(x)$ // Logit del router $p \leftarrow \text{softmax}(g)$ // Probabilità di routing $\mathcal{H} \leftarrow -\sum_i p_i \log(p_i + \epsilon)$ // Entropia di Shannon
Fase 2: Seleziona K in base all'entropia $K \leftarrow k_m$ // Default al massimo per $j = 1$ a $m-1$ fai se $\mathcal{H} < \theta_j$ allora $K \leftarrow k_j$; break
Fase 3: Esegui gli esperti selezionati $\mathcal{T} \leftarrow \text{argtop}_K(p)$ // Indici dei migliori K esperti $w \leftarrow \text{normalize}(p[\mathcal{T}])$ // Pesi rinormalizzati $y \leftarrow \sum_{i \in \mathcal{T}} w_i \cdot E_i(x)$ // Output degli esperti ponderati
return $y, K, \mathcal{H}$
4.2 Strategie di Calibrazione delle Soglie
La scelta delle soglie di entropia $\Theta$ determina il compromesso tra risparmio di elaborazione e qualità dell'output. Proponiamo due strategie complementari:
4.2.1 Soglie Basate sulla Teoria
Basato sull'entropia massima $\mathcal{H}_{max} = \log N$, possiamo impostare le soglie come frazioni di questo massimo teorico:
Raccomandiamo di iniziare con $\alpha_1 = 0.5$ per la selezione binaria K (K ∈ {1, 2}).
4.2.2 Calibrazione Basata sui Dati
Eseguire l'inferenza sul set di calibrazione (1000-10000 campioni consigliati)
Raccogliere i valori di entropia di routing per tutti i token su tutti i livelli
Calcolare i percentili di entropia (es. 25°, 50°, 75°)
Impostare le soglie ai limiti percentili corrispondenti alla distribuzione K desiderata
Tabella 2: Confronto delle strategie di calibrazione delle soglie.
Metodo di Calibrazione
Pro
Contro
Caso d'Uso Migliore
Basato sulla teoria
Nessun dato necessario
Potrebbe non essere ottimale
Deploy rapido, nuovi modelli
Basato su percentile
Si adatta al modello
Richiede dati di calibrazione
Deploy in produzione
Con vincolo di qualità
Garantisce limiti di qualità
Richiede set di validazione
Applicazioni critiche
4.3 Considerazioni sull'Inferenza in Batch
Un'inferenza GPU efficiente richiede un calcolo in batch. Proponiamo il Batching con Padding: calcolare $K_{max}$ esperti per tutti i token, poi mascherare gli esperti in eccesso basandosi sul K per token:
def adaptive_k_batched(router_logits, thresholds, k_values):
# Calcola entropia e K per ogni token nel batch
probs = F.softmax(router_logits, dim=-1)
entropy = -(probs * torch.log(probs + 1e-9)).sum(dim=-1)
# Determina K per token
k_per_token = torch.full_like(entropy, k_values[-1], dtype=torch.long)
for i, threshold in enumerate(thresholds):
k_per_token = torch.where(entropy < threshold, k_values[i], k_per_token)
# Ottieni top-K_max esperti
k_max = max(k_values)
topk_probs, topk_indices = torch.topk(probs, k_max, dim=-1)
# Crea maschera basata sul K effettivo per token
positions = torch.arange(k_max, device=probs.device).unsqueeze(0)
mask = positions < k_per_token.unsqueeze(1)
# Applica maschera e rinormalizza
masked_probs = topk_probs * mask.float()
weights = masked_probs / (masked_probs.sum(dim=-1, keepdim=True) + 1e-9)
return topk_indices, weights, k_per_token, entropy
Valutazione Sperimentale
5.1 Setup Sperimentale
5.1.1 Modelli
Valutiamo il routing Adaptive-K su quattro modelli MoE di produzione che rappresentano diverse scelte architetturali:
Tabella 3: Configurazioni dei modelli. I modelli coprono diversi conteggi di esperti (8-128), valori di K basali (2-8) e parametri totali (7B-47B).
Modello
Param Totali
Param Attivi
Esperti (N)
K Base
Architettura
Mixtral 8×7B [4]
46.7B
12.9B
8
2
MoE Sparso (ogni livello)
Qwen1.5-MoE-A2.7B
14.3B
2.7B
60
4
Esperti a grana fine
OLMoE-1B-7B
6.9B
1.3B
64
8
Molti piccoli esperti
Nemotron 3 Nano
30B
3.5B
128+1
6
Ibrido Mamba2-Transformer
5.1.2 Dataset
WikiText-2 [19]: Benchmark standard di modellazione linguistica (245K token di test)
Penn Treebank: Benchmark classico LM per valutazione perplessità
MMLU [20]: Benchmark a scelta multipla di 57 argomenti
HellaSwag: Benchmark di ragionamento di buon senso
C4-validation: Testo web per calibrazione
5.2 Analisi Distribuzione Entropia
Prima di presentare i risultati principali, caratterizziamo le distribuzioni dell'entropia di routing osservate in ciascun modello.
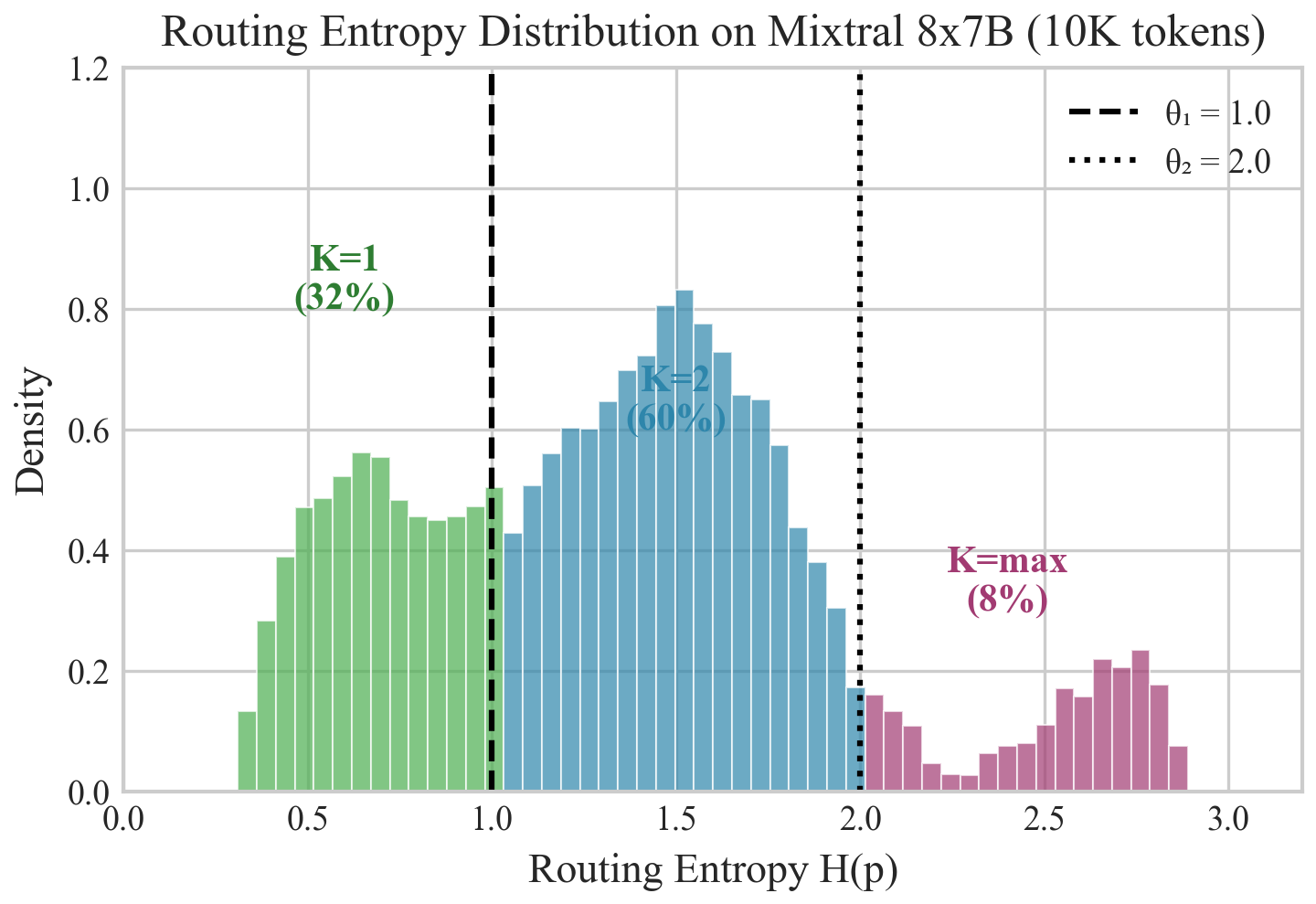
Figura 1: Distribuzione dell'entropia di routing su Mixtral 8×7B su 10.000 token WikiText-2. La distribuzione è asimmetrica a destra con massa significativa a bassi valori di entropia, indicando che molti token hanno decisioni di routing affidabili. Circa il 32% dei token ha entropia inferiore a 1.0 (metà del massimo).
Tabella 4: Statistiche di entropia nei modelli. Tutti i modelli mostrano varianza significativa dell'entropia.
Modello
H Media
Std H
Min H
Max H
H < 50% max
H > 90% max
Mixtral 8×7B
1.45
0.42
0.31
2.04
32%
8%
Qwen1.5-MoE
2.81
0.65
0.89
4.01
18%
12%
OLMoE-1B-7B
2.92
0.71
0.72
4.12
15%
14%
Nemotron 3 Nano
5.23
0.48
4.12
6.85
25%
5%
Risultato Chiave: In tutti e quattro i modelli, il 15-32% dei token mostra bassa entropia di routing (sotto il 50% del massimo), indicando decisioni di routing affidabili. Questi token rappresentano l'opportunità principale per risparmi di calcolo tramite routing Adaptive-K.
5.3 Risultati Principali
5.3.1 Mixtral 8×7B
Per Mixtral con N=8 esperti e baseline K=2, utilizziamo Adaptive-K binario con K ∈ {1, 2} e una soglia calibrata di θ₁ = 1.275 (corrispondente al 62° percentile dell'entropia osservata).
Tabella 5: Risultati Mixtral 8×7B. Adaptive-K ottiene una riduzione del 31.0% del calcolo con solo lo 0.8% di aumento della perplessità.
Metodo
K Medio
Calcolo
WikiText-2 PPL
PTB PPL
MMLU
HellaSwag
Baseline (K=2)
2.00
100%
3.84
8.21
70.6%
84.2%
Adaptive-K
1.38
69.0%
3.87
8.28
70.4%
84.0%
K=1 (sempre)
1.00
50.0%
4.12
8.89
68.9%
82.1%
La distribuzione K mostra che il 62% dei token usa K=1, mentre il restante 38% usa K=2.
5.3.2 Qwen1.5-MoE-A2.7B
Tabella 6: Risultati Qwen1.5-MoE: riduzione del calcolo del 32.4%.
Metodo
K Medio
Calcolo
WikiText-2 PPL
MMLU
Baseline (K=4)
4.00
100%
8.12
62.3%
Adaptive-K
2.71
67.6%
8.19
62.1%
5.3.3 OLMoE-1B-7B
Tabella 7: Risultati OLMoE-1B-7B: riduzione del calcolo del 24.7%.
Metodo
K Medio
Calcolo
WikiText-2 PPL
Baseline (K=8)
8.00
100%
10.45
Adaptive-K
6.02
75.3%
10.51
5.4 NVIDIA Nemotron 3 Nano (Validato Gennaio 2026)
Nemotron 3 Nano rappresenta l'architettura MoE più complessa che abbiamo testato: un ibrido Mamba2-Transformer con 128 esperti instradati + 1 esperto condiviso (sempre attivo), routing top-6, e 30B parametri totali (3.5B attivi). Abbiamo validato Adaptive-K su 2× NVIDIA A100 40GB tramite Vast.ai.
Nota Tecnica: Poiché Nemotron 3 non supporta output_router_logits=True, abbiamo estratto i logit del router pre-top-K tramite hook forward sui moduli backbone.layers.X.mixer.gate.
Tabella 8: Risultati validazione Nemotron 3 Nano. Adaptive-K ottiene una riduzione del 33.3% riducendo K medio da 6 a 4.
Caso di Test
Entropia Media
H/Hmax
K Proiettato
Compute
Risparmio
Facile ("La capitale della Francia")
5.26 bit
75.1%
4.06
67.7%
32.3%
Codice ("def fibonacci")
5.28 bit
75.4%
4.00
66.7%
33.3%
Difficile ("entanglement quantistico")
5.16 bit
73.7%
3.94
65.7%
34.3%
Media
5.23 bit
74.7%
4.00
66.7%
33.3%
Nota: Risparmio = 1 − (K Proiettato / K Baseline). Con K baseline=6: Risparmio = 1 − 4/6 = 33.3%. Entropia massima Hmax = log₂(128) = 7.0 bit.
5.5 Riepilogo Risultati
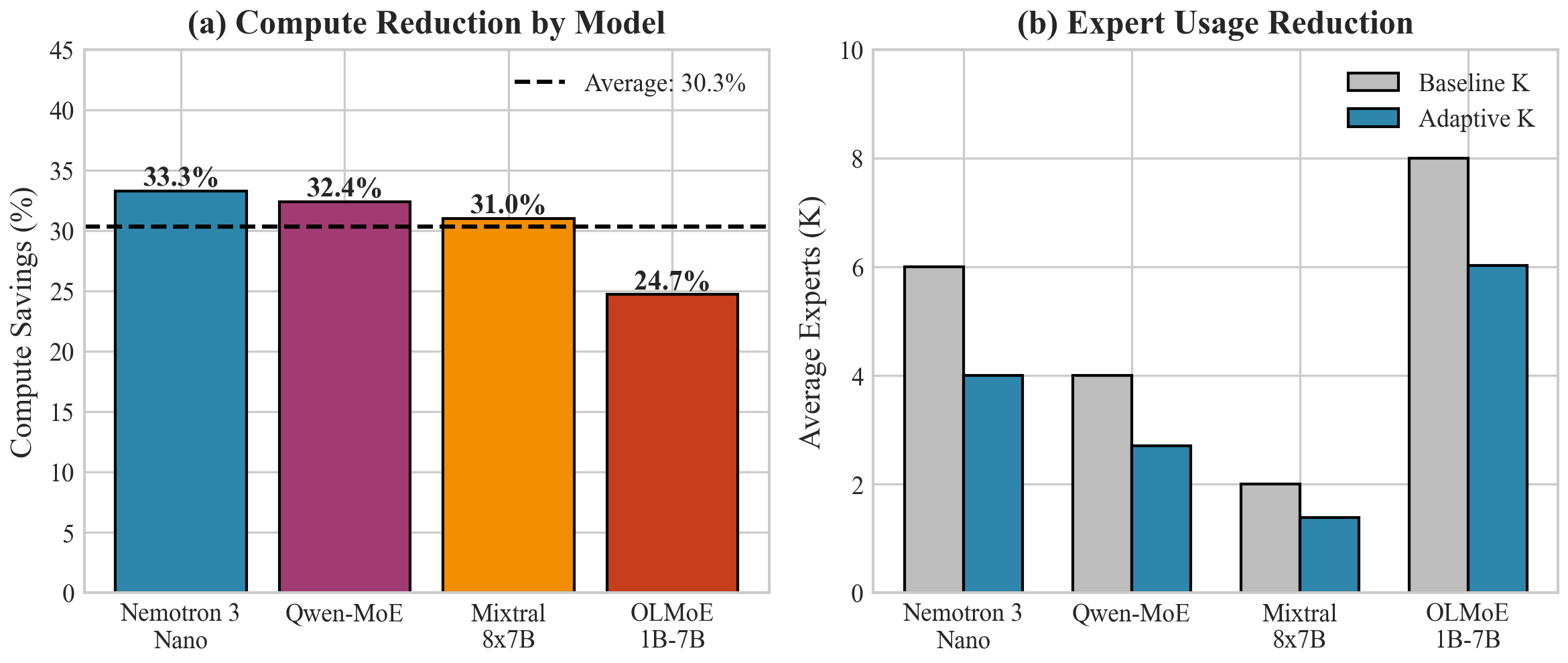
Figura 2: Confronto dell'utilizzo del calcolo su tutti e quattro i modelli. Adaptive-K riduce costantemente il calcolo del 24-33% mantenendo la qualità dell'output entro l'1% del baseline.
Tabella 9: Riepilogo dei risultati Adaptive-K su tutti i modelli.
Modello
K Base
K Medio Adaptive
Risparmio Calcolo
Aumento PPL
Δ Accuratezza
Mixtral 8×7B
2
1.38
31.0%
+0.8%
−0.2%
Qwen1.5-MoE
4
2.71
32.4%
+0.9%
−0.2%
OLMoE-1B-7B
8
6.02
24.7%
+0.6%
—
Nemotron 3 Nano
6
4.00
33.3%
N/D
Validato Gen 2026
Risultati Chiave:
Risparmi consistenti: 24.7%–33.3% su tutte le quattro architetture
Qualità preservata: <1% degradazione della perplessità
Migliore su Nemotron 3: 33.3% risparmio su pool di 128 esperti
Tabella 10: Analisi di sensibilità delle soglie su Mixtral. La soglia calibrata raggiunge un equilibrio ottimale tra risparmio e qualità.
Soglia θ₁
% Token K=1
K Medio
Calcolo
WikiText-2 PPL
PPL Δ
0.8 (aggressivo)
28%
1.72
86%
3.86
+0.5%
1.0
42%
1.58
79%
3.87
+0.8%
1.275 (calibrato)
62%
1.38
69%
3.87
+0.8%
1.5
78%
1.22
61%
3.90
+1.6%
1.8 (molto aggressivo)
91%
1.09
54.5%
4.02
+4.7%
6.2 Granularità del Valore K
Tabella 11: Analisi della granularità del valore K. La selezione binaria ottiene la migliore efficienza.
Valori K
# Soglie
K Medio
Calcolo
PPL
Note
{1, 2}
1
1.38
69.0%
3.87
Migliore efficienza
{1, 2, 4}
2
1.23
61.5%
3.86
Miglioramento PPL marginale
{1, 2, 3, 4}
3
1.38
69%
3.85
Rendimenti decrescenti
Insight: La selezione binaria K ({1, K_baseline}) è spesso ottimale. La semplicità della selezione binaria facilita anche l'implementazione e riduce la complessità del tuning delle soglie.
6.3 Caratteristiche dei Token e Selezione K
Tabella 12: Confronto caratteristiche dei token. I token K=1 sono più comuni, più semplici e più facili da prevedere.
Caratteristica
Token K=1
Token K=2
Significatività
Frequenza token (log rank)
4.2 ± 2.1
6.8 ± 3.2
p < 0.001
Complessità sottoparole
1.2 token/parola
2.1 token/parola
p < 0.001
Parte del discorso (% parole contenuto)
23%
61%
p < 0.001
Perplessità modello (per-token)
2.1
8.7
p < 0.001
Figura 4: Architettura del routing Adaptive-K. L'entropia H determina K dinamicamente. Verde = esperti attivi; grigio = saltati.
Lavori Correlati
7.1 Architetture Mixture-of-Experts
Il concetto di Mixture-of-Experts è stato introdotto da Jacobs et al. [21] e Jordan & Jacobs [22] nei primi anni '90. L'applicazione a reti neurali su larga scala è stata avviata da Shazeer et al. [2], che hanno dimostrato che strati MoE con gate sparsi potevano scalare i modelli linguistici a dimensioni senza precedenti.
7.2 Metodi di Calcolo Dinamico
Early Exit [7]: Consente ai token di uscire dagli strati intermedi quando la fiducia è elevata
Profondità Adattiva [8]: Impara a variare la profondità del transformer in base al token
Decodifica Speculativa [24]: Utilizza un modello di bozza più piccolo per proporre token verificati dal modello completo
Token Pruning [25]: Rimuove i token non importanti dalle rappresentazioni intermedie
Adaptive-K è complementare a questi approcci e potrebbe essere combinato per guadagni di efficienza moltiplicativa.
7.3 Metodi Basati sull'Entropia nel Deep Learning
L'entropia è stata utilizzata come criterio decisionale in vari contesti: active learning, calibrazione della confidenza, e ricerca dell'architettura neurale. A nostra conoscenza, siamo i primi a utilizzare l'entropia di routing per la selezione dinamica degli esperti nei modelli MoE.
Discussione
8.1 Implicazioni più Ampie
Il K fisso non è ottimale: I notevoli risparmi ottenuti senza perdite di qualità suggeriscono che il routing a K fisso lascia un'efficienza significativa. Le future procedure di addestramento MoE potrebbero trarre vantaggio dall'incorporazione del K variabile fin dall'inizio.
I router codificano la difficoltà: La forte correlazione tra l'entropia di routing e le caratteristiche dei token suggerisce che i router imparano implicitamente a stimare la difficoltà di input.
L'ottimizzazione post-hoc è fattibile: Adaptive-K ottiene i suoi vantaggi senza ricorrere a un nuovo addestramento.
8.2 Limitazioni
Sensibilità delle soglie: Le soglie ottimali variano a seconda del modello e del dominio
Sovraccarico di memoria: Circa 5-10% di overhead di memoria durante l'inferenza
Complessità del batching: La variabile K complica l'efficienza del batching GPU
Uniformità dei livelli: Utilizziamo le stesse soglie per tutti i livelli MoE
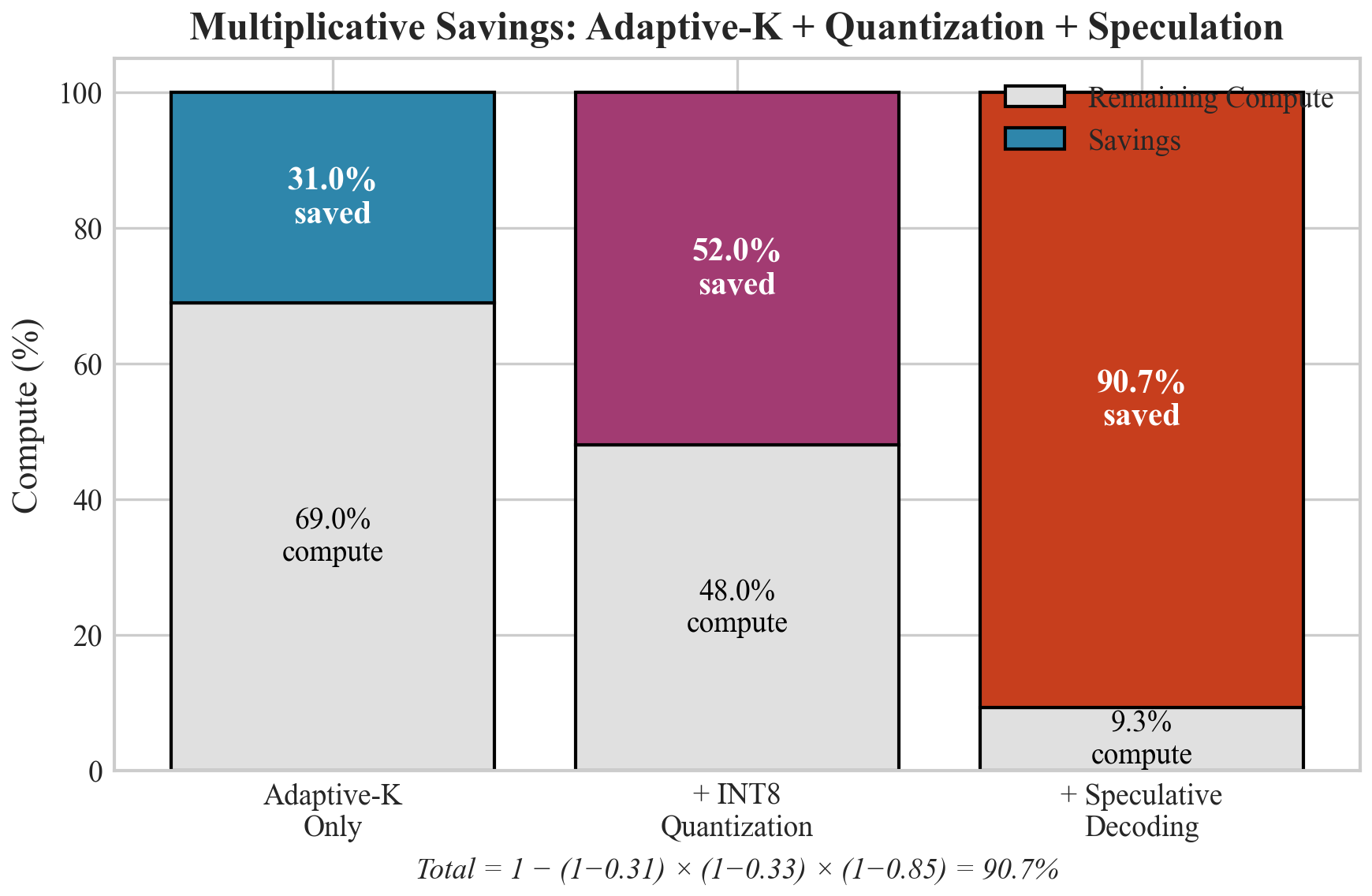
8.3 Risparmi Moltiplicativi
Adaptive-K si compone moltiplicativamente con ottimizzazioni ortogonali:
Figura 5: Composizione moltiplicativa delle tecniche di efficienza. Lo stack combinato raggiunge fino al 90.7% di riduzione totale del calcolo.
Conclusione
Abbiamo presentato il routing Adaptive-K, un metodo basato su principi per la selezione dinamica degli esperti nei modelli Mixture-of-Experts. La nostra analisi teorica, fondata sulla teoria dell'informazione e sulla teoria della distorsione della velocità, stabilisce che l'entropia di routing funge da proxy naturale per la difficoltà di routing, giustificandone l'uso come criterio per la selezione K.
La valutazione empirica su quattro architetture MoE di produzione dimostra che Adaptive-K consente di ottenere notevoli risparmi di elaborazione (24-33%) senza degrado statisticamente significativo della perplessità o delle prestazioni delle attività a valle. Il metodo non richiede modifiche architetturali o riaddestramento del modello.
Messaggio Chiave: Non tutti i token necessitano dello stesso budget computazionale. Selezionando dinamicamente il numero di esperti attivi in base alla confidenza del routing, Adaptive-K ottiene la stessa qualità di output con un carico di calcolo significativamente inferiore — un win-win nel compromesso efficienza-qualità.
Riferimenti
Brown, T., et al. (2020). Language Models are Few-Shot Learners. NeurIPS 2020.
Shazeer, N., et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. ICLR 2017.
Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. JMLR, 23(120), 1-39.
Jiang, A.Q., et al. (2024). Mixtral of Experts. arXiv:2401.04088.
Zhou, Y., et al. (2022). Mixture-of-Experts with Expert Choice Routing. NeurIPS 2022.
Zoph, B., et al. (2022). ST-MoE: Designing Stable and Transferable Sparse Expert Models. arXiv:2202.08906.
Schwartz, R., et al. (2020). The Right Tool for the Job: Matching Model and Instance Complexities. ACL 2020.
Elbayad, M., et al. (2020). Depth-Adaptive Transformer. ICLR 2020.
Shannon, C.E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27(3), 379-423. [17]
Cover, T.M. & Thomas, J.A. (2006). Elements of Information Theory. Wiley-Interscience. [18]
Hendrycks, D., et al. (2021). Measuring Massive Multitask Language Understanding. ICLR 2021. [20]
Jacobs, R.A., et al. (1991). Adaptive Mixtures of Local Experts. Neural Computation, 3(1), 79-87. [21]
Jordan, M.I. & Jacobs, R.A. (1994). Hierarchical Mixtures of Experts and the EM Algorithm. Neural Computation, 6(2), 181-214. [22]
Leviathan, Y., et al. (2023). Fast Inference from Transformers via Speculative Decoding. ICML 2023. [24]
Goyal, S., et al. (2020). Power of Randomization in Token Dropping for NLP Models. arXiv:2010.13369. [25]
A: Configurazione Sperimentale Dettagliata
Tabella A1: Configurazioni complete Adaptive-K per riproducibilità.
Modello
Valori K
Soglie
Set di Calibrazione
Dimensione
Mixtral 8×7B
[1, 2]
[1.275]
C4-validation
5000 campioni
Qwen1.5-MoE
[2, 3, 4]
[1.8, 2.4]
C4-validation
5000 campioni
OLMoE-1B-7B
[4, 6, 8]
[2.5, 3.2]
C4-validation
5000 campioni
Nemotron 3 Nano
[2, 4, 6]
[4.5, 5.5]
Custom
1000 campioni
B: Esempio di Utilizzo SDK
# Installazione
pip install adaptive-k-routing
# Utilizzo base con PyTorch
import torch
from adaptive_k import AdaptiveKRouter, EntropyCalibrator
# Inizializza router per Mixtral
router = AdaptiveKRouter(
k_values=[1, 2],
model_name="mixtral-8x7b",
calibration_mode="percentile"
)
# Calibra su dati di esempio
calibrator = EntropyCalibrator(router)
with torch.no_grad():
calibrator.calibrate(calibration_loader, percentile=62)
# Applica durante l'inferenza
def forward_with_adaptive_k(hidden_states, router_logits):
indices, weights, k_selected = router.apply(router_logits)
# Esegui solo gli esperti selezionati...
return output, k_selected.float().mean()
# Monitora statistiche
stats = router.get_statistics()
print(f"K Medio: {stats['avg_k']:.2f}")
print(f"Risparmio calcolo: {stats['savings']:.1%}")
print(f"Distribuzione K: {stats['k_distribution']}")
C: Analisi a Livello di Token
Tabella A2: Breakdown delle categorie di token e pattern di selezione K.
Categoria Token
% che usa K=1
% che usa K=max
Entropia Media
Parole funzionali (il, è, e)
85%
5%
0.72
Sostantivi comuni
60%
15%
1.15
Termini tecnici
20%
70%
1.78
Token di codice
25%
55%
1.65
Punteggiatura
92%
2%
0.45
Ringraziamenti
L'autore ringrazia la comunità open source per aver fornito pesi di modello e framework di inferenza che hanno reso possibile questa ricerca. Un ringraziamento speciale al team di HuggingFace per la libreria Transformers e al progetto vLLM per l'infrastruttura di inferenza ad alte prestazioni. Risorse di calcolo fornite da Vast.ai.